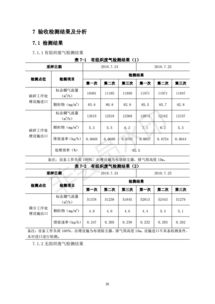
在榮成市全力推進(jìn)高質(zhì)量發(fā)展的新征程中,東山街道立足區(qū)位優(yōu)勢(shì)與發(fā)展實(shí)際,敏銳把握時(shí)代機(jī)遇,將城鄉(xiāng)生活垃圾治理作為撬動(dòng)全域提升、謀求全面突破的關(guān)鍵支點(diǎn),系統(tǒng)謀劃,精準(zhǔn)施策,走出了一條生態(tài)效益與治理效能雙贏的創(chuàng)新之路。
一、 提高站位,將垃圾治理融入發(fā)展大局
東山街道深刻認(rèn)識(shí)到,優(yōu)美整潔的人居環(huán)境是吸引投資、匯聚人才、提升群眾幸福感的基礎(chǔ),更是實(shí)現(xiàn)可持續(xù)發(fā)展的重要保障。街道黨工委、辦事處將生活垃圾全程分類與無(wú)害化、資源化處理工作,提升到推動(dòng)鄉(xiāng)村振興、優(yōu)化營(yíng)商環(huán)境、建設(shè)精致城市的戰(zhàn)略高度進(jìn)行部署。通過(guò)建立“一把手”負(fù)責(zé)制與部門聯(lián)動(dòng)機(jī)制,明確責(zé)任分工,將垃圾治理成效納入社區(qū)、村居年度考核體系,形成了“街道主導(dǎo)、社區(qū)(村)落實(shí)、群眾參與、齊抓共管”的工作格局。
二、 系統(tǒng)施策,構(gòu)建全鏈條治理體系
- 源頭減量與精準(zhǔn)分類: 街道持續(xù)加大宣傳引導(dǎo)力度,通過(guò)入戶宣講、設(shè)立宣傳欄、開(kāi)展主題活動(dòng)等多種形式,普及垃圾分類知識(shí),倡導(dǎo)綠色生活方式。在居民小區(qū)、農(nóng)村社區(qū)合理布局分類投放點(diǎn),配備標(biāo)識(shí)清晰的收集容器,并逐步推廣智能分類設(shè)備,引導(dǎo)居民養(yǎng)成主動(dòng)分類、精準(zhǔn)投放的習(xí)慣。鼓勵(lì)商超、農(nóng)貿(mào)市場(chǎng)減少一次性用品使用,從源頭減少垃圾產(chǎn)生量。
- 收運(yùn)體系優(yōu)化升級(jí): 針對(duì)以往收運(yùn)環(huán)節(jié)存在的混裝混運(yùn)問(wèn)題,東山街道投入專項(xiàng)資金,更新配備了分類運(yùn)輸車輛,嚴(yán)格實(shí)行“不同種類、不同車輛、不同去向”的分類收運(yùn)模式。科學(xué)規(guī)劃收運(yùn)路線與時(shí)間,確保分類后的垃圾能夠及時(shí)、高效地運(yùn)往指定處理場(chǎng)所,杜絕“前端分類、后端混合”的現(xiàn)象,維護(hù)居民分類積極性。
- 終端處理與資源利用: 街道積極配合市級(jí)統(tǒng)籌,確保分類后的垃圾進(jìn)入相應(yīng)的處理終端。可回收物進(jìn)入資源回收體系,變廢為寶;有害垃圾得到安全處置;廚余垃圾積極探索就地處理或集中資源化利用模式;其他垃圾實(shí)現(xiàn)全量焚燒發(fā)電。通過(guò)完善終端處理設(shè)施網(wǎng)絡(luò),極大提升了垃圾的資源化利用率與無(wú)害化處理水平。
三、 創(chuàng)新驅(qū)動(dòng),探索長(zhǎng)效管理機(jī)制
東山街道注重運(yùn)用科技與制度創(chuàng)新鞏固治理成果。試點(diǎn)引入“智慧環(huán)衛(wèi)”管理平臺(tái),對(duì)垃圾投放、收運(yùn)、處理等環(huán)節(jié)進(jìn)行數(shù)字化監(jiān)控與調(diào)度,提升管理效率。探索建立垃圾分類積分獎(jiǎng)勵(lì)制度,居民可通過(guò)正確分類獲取積分,兌換生活用品或社區(qū)服務(wù),激發(fā)參與熱情。鼓勵(lì)社會(huì)資本參與垃圾資源化利用項(xiàng)目,推動(dòng)形成政府引導(dǎo)、市場(chǎng)運(yùn)作、社會(huì)協(xié)同的多元共治局面。
四、 成效初顯,助力全面突破發(fā)展
通過(guò)一系列扎實(shí)舉措,東山街道生活垃圾治理工作取得了顯著成效:街道面貌更加干凈整潔,垃圾分類知曉率、參與率、準(zhǔn)確率穩(wěn)步提升,資源回收利用率明顯提高。人居環(huán)境的改善,直接提升了轄區(qū)居民的獲得感與滿意度,也為街道招商引資、發(fā)展文旅產(chǎn)業(yè)、打造美麗鄉(xiāng)村提供了優(yōu)質(zhì)的生態(tài)基底和形象名片。生活垃圾治理的“小切口”,正有效推動(dòng)著東山街道在社會(huì)治理、生態(tài)環(huán)境、經(jīng)濟(jì)發(fā)展等領(lǐng)域的“全面突破”。
榮成市東山街道將繼續(xù)堅(jiān)持問(wèn)題導(dǎo)向與目標(biāo)導(dǎo)向,持續(xù)深化生活垃圾綜合治理改革,不斷鞏固和擴(kuò)大治理成果,為榮成市建設(shè)“深藍(lán)、零碳、精致、幸福”的現(xiàn)代化新榮成貢獻(xiàn)更多東山力量。